人工知能・データサイエンスブームがはじまってからはや数年、自然科学研究においてもデータサイエンスは一過性のものではなく、研究に当たり前に使われる未来が容易に想像できるところまできているようにも見えます。筆者のまわりの有機化学研究者からも、Pythonの勉強をはじめた、といった声を頻繁に聞きます。
一方でPythonなどのインフォマティクスのためのツールを勉強したものの、どのように研究に活かせばよいかわからないといった声も多く聞きます。ここでタイトルの問いが頭に浮かびます。
有機化学者・実験化学者が機械学習/ケモインフォマティクスを用いた研究をはじめるのに共同研究は必要でしょうか?(ここでいう共同研究とは異分野の研究者にデータ解析を委託するものを指します)
いろいろな考え方があるかと思いますが、機械学習/ケモインフォマティクスでよく目にする回帰分析に関して個人的な意見を言えば、答えはNOであると思います。この理由を説明するのに便利な言葉が以下になります。
「機械学習はデータ前処理までが8割」
つまりケモインフォマティクス研究において機械学習手法自体の比重は高くないということです。このことを有機合成分野でよく行われている触媒反応の回帰分析で説明してみます。触媒反応の回帰分析のプロセスを図に示しました。
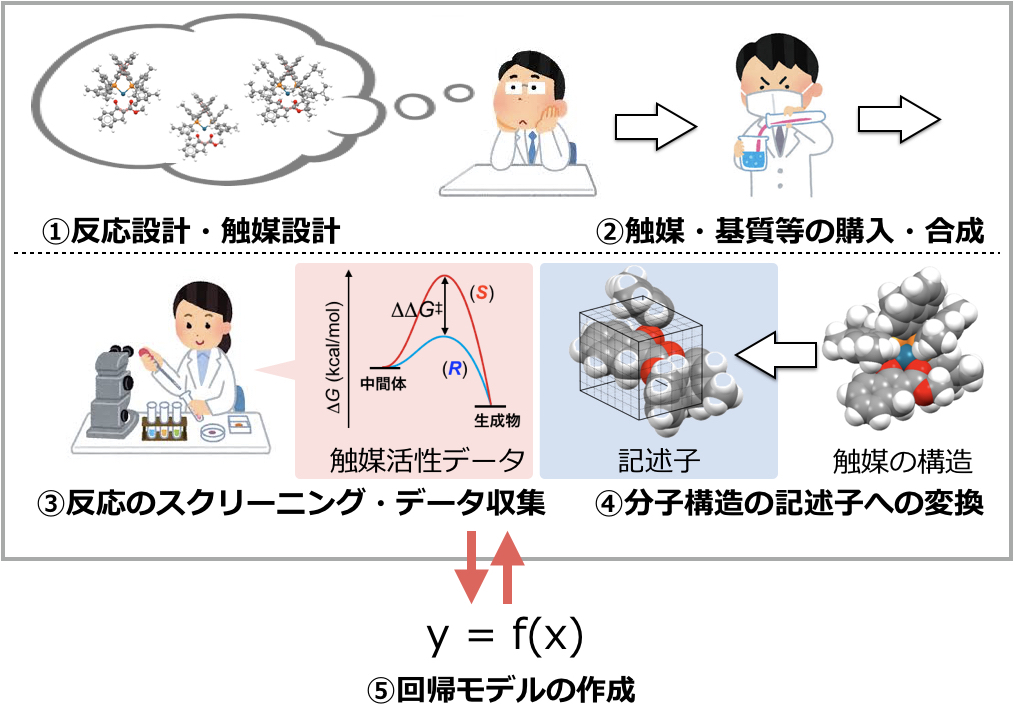
- 解析対象の決定:まず最初に解析したい触媒反応を定めます。
- 基質・触媒準備:次に反応データ収集のための触媒や基質を準備します。
- 解析データ収集:触媒反応のスクリーニングを行い触媒活性データを収集します。
- 記述子への変換:スクリーニングした触媒や基質分子の構造・性質を数値化し記述子とします。
- 回帰モデル作成:集めた触媒活性データと記述子とを機械学習手法を用いて相関付し回帰モデルをつくります。得られた結果をもとに各プロセスをブラッシュアップし、解析の質をあげていきます。
上記プロセスから分かる通り、反応の回帰分析において機械学習手法が活躍するのは最後の5.の段階のみです。機械学習手法を線形回帰に限定しても、1.~4.の8割の部分を突き詰めれば、自ずとオリジナリティの高いデータ解析研究につながります。自分で実験データを集められる実験化学者は、どのような触媒反応を解析するかを含む8割の部分を自分の思い通りに設定できます。すなわち有機合成化学者はオリジナリティの高いデータ解析研究をしやすいと筆者は考えています。機械学習手法は線形回帰に固定してしまってよいのではと思います。
計算機が高速化し、情報科学の発展により様々なツールが手軽に使えるようになった今、データサイエンスは、フラスコのなかで起こる反応や現象をどうにかして表現したいという思いを持つ実験化学者にとって非常にエキサイティングな分野だと考えています。どのような反応・現象を対象にするか、どういった解析データを用いるか、どういう記述子を用いて、どのように反応をデータ解析により定量化・表現するか、これらには研究者の個性を色濃く反映させることが可能です。研究はよく芸術に例えられますが、データ解析研究も上記のように研究者の個性を色濃くあらわすことができるという点で、アーティスティックな側面の強い研究分野だと思っています。
そんなこといってもどういう触媒活性を集めればよいのか、記述子はどうやって計算すればよいのか、線形回帰で十分といわれてもそもそも線形回帰をどう使えばよいのか、などの疑問点も多々でてくるかと思います。はじめにで述べたように、有機合成化学を専門とする筆者が立ち上げたデータ駆動型触媒設計研究の経験に基づき、本サイトでは有機合成化学者が自力でデータ解析研究を論文化するのに役に立つであろう情報を提供していきます。
研究を論文化するためには「巨人の肩の上に立つ」、すなわち先人たちの仕事について把握する必要があります。有機化学における回帰に基づくデータ科学は、本ブログで取り扱う少数サンプルの解析においては、少なくとも100年近い歴史のある分野です。次回は、有機反応におけるデータ科学・回帰分析の簡単な歴史・背景知識について説明していきます。
コメント